As promised, I have been playing with Dynamic Data Masking and here are some things I have learned. I downloaded World Wide Importers so I would have a place to play and there were masked columns already included.
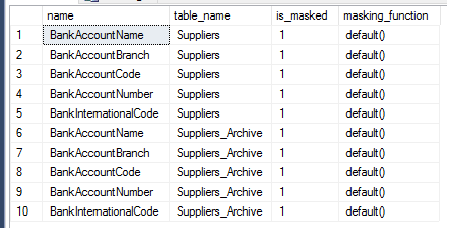
This query will show us what has already been masked:
SELECT mc.name, t.name as table_name, mc.is_masked, mc.masking_function
FROM sys.masked_columns AS mc
JOIN sys.tables AS t
ON mc.[object_id] = t.[object_id]
WHERE is_masked = 1;
Here we can see the column and the table that is being masked and what masking function is being used.
This is a great time to talk about the different masking functions and what they do. The four types in 2016 are Default, Email, Random and Custom String.
Default – For numeric and binary it will show a “0” For a date it will show 01/01/1900 and for strings it will show xxxx’s (more or less depending on the size of the field).
Email – It will expose the first letter of the email address and the suffix at the end of the email (.com, .net, .edu etc.) For example Batgirl@DC.com would now be bxxx@xxxx.com.
Random – Number randomly generated between a set range. Kind of like the game, “Pick a number between 1 and 10” but for SQL.
Custom String – Lets you get creative with how much you show or cover and what you use to cover (not stuck with just xxxx’s).
Now for fun, let’s create a table that will be masked.
CREATE TABLE SuperHero
(HeroId INT IDENTITY PRIMARY KEY
,HeroName VARCHAR(100)
,RealName VARCHAR(100) MASKED WITH (FUNCTION = 'partial(1,"XXXXXXX",0)') NULL
,HeroEmail VARCHAR(100) MASKED WITH (FUNCTION = 'email()') NULL
,PhoneNumber VARCHAR(10) MASKED WITH (FUNCTION = 'default()') NULL);
Let’s add some data that we will want to mask:
INSERT SuperHero (HeroName, RealName, HeroEmail, PhoneNumber) VALUES
('Batman', 'Bruce Wayne', 'batsy@heros.com', '5558675309' ),
('Superman', 'Clark Kent', 'manofsteel@heros.com','5558675308' ),
('Spiderman', 'Peter Parker', 'spidey@heros.com','5558675307' );
SELECT * FROM SuperHero;
and finally we add some low level permissions of people who will look at the masked version of the data:
CREATE USER CommonPeople WITHOUT LOGIN;
GRANT SELECT ON SuperHero TO CommonPeople;
Now the test to see if CommonPeople have access to see all of our Superhero secrets:
EXECUTE AS USER = 'CommonPeople';
SELECT * FROM SuperHero;
REVERT;
Try it out and see for yourself how it looks. Now you have experienced Dynamic Data Masking 101 in SQL Server 2016!
The song for this post is Good Charlotte – Keep Your Hands Off My Girl